So geht Crawling / Scraping von SPAs extra schnell und einfach!
Herausforderung Single Page Applications
Im Bereich Webscraping sind Single Page Applications (SPAs) eine besondere Herausforderung. Sie sind meistens in fancy Javascript-Frontend-Frameworks wie Reacht, AngularJS oder vueJS geschrieben und laden ihre Inhalte erst nach Seitenaufruf via Javascript nach. Dies ist für typische Python-Libraries wie request ein großes Problem, da diese Websites kein einfaches HTML bei dem initiale HTTP-Request zurückliefern. Meistens geben SPAs sogar nur ein karges HTML-Dokument mit dem Text „Bitte aktivieren Sie Javascript!“ zurück.
Wenn die Entwickler/innen der Single Page Application sogar noch ein bisschen was auf dem Kasten hatten, haben sie den Server sogar noch so konfiguriert, dass du bzw. deine IP nach ein paar Requests einen Timeout erhält. Single Page Applications zu crawlen ist die Hölle!
Scrapingbee – Einfach Single Page Applications crawlen / scrapen
Ich werde in diesem Beitrag nur einen Weg vorstellen SPAs in Python vorstellen – den einfachsten und schnellsten, den ich gefunden habe. Mehr Infos zu meinen spezifischen Anwendungsfällen gibt es im nächsten Abschnitt. Ich habe ein kleines Tool entdeckt mit dem Namen Scrapingbee. Das Unternehmen hinter Scrapingbee sitzt in Frankreich (Paris) und stellt eine einfach API für seine Services bereits. Seine Technologie ist flexibel genug, um Single Page Applications zu crawlen und lässt sich einfach in Python integrieren.
Mit diesem kleinen Code Snippet erhalte ich alle Infos, die ich für meinen Fall von einer Website bzw. mehreren Unterseiten-benötige.
(Python Code)
# pip install scrapingbee
from scrapingbee import ScrapingBeeClient
import urllib.parse # just to make the response pretty
## Define list of URLs you want to crawl / scrape
urllist = ["https://www.remind.me/", "https://www.remind.me/strom/ratgeber/strommessgeraete-helfen-beim-energiesparen"]
## initiate ScrapingBee Client
client = ScrapingBeeClient(api_key="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
## loop through all urls in my list to extract information
for url in urllist:
response = client.get(url,
params = {
# render the SPA javascript
'render_js': 'True',
# do not block any important ressources
'block_resources': 'False',
# wait 2 seconds for the SPA to load
'js_scenario': {"instructions": [{"wait": 2000}]},
# return a json response
'json_response': 'True',
# only return the titel and meta description
'extract_rules': {"title": "title", "description": "//meta[@name=\"description\"]/@content"},
}
)
# prettify response
prettyResponse = response.json()
# print the repsonse content to the terminal or do whatever you want with it
print(prettyResponse['body'])Das Tool erstellt über seinen Client einen API Request, der weitere Specs zur Art und Weise des Crawls beinhaltet. So habe ich folgende Anforderung auf Basis der SPA, die ich crawlen möchte. Diese kann ich durch das „param“ Objekt spezifizieren:
- Es soll das Javascript auf der Zielseite ausgeführt werden (render_js) und keine Ressourcen geblockt werden (block_resources)
- Dann bitte eine Sekunde warten für den Fall, dass die Skripte etwas brauchen (js_scenario + wait)
- Ich hätte gerne eine Json-Response (json_response)
- Und via extract_rules definiere ich via CSS-Selektor oder X-Path welche Informationen ich von der Seite benötige (ich brauche traditionell nicht alle Inhalte).
Mit der Response kann ich dann machen, was ich möchte. Einfach ins Terminal schreiben oder das Ganze am Ende in eine CSV schreiben, damit ich sie weiter analysieren kann. Ich könnte die Response sogar nach Links durchsuchen und nochmal in einen Scrapingbee-Call packen.
Als Response, erhalte ich nur das, was ich wirklich von der Seite benötige:

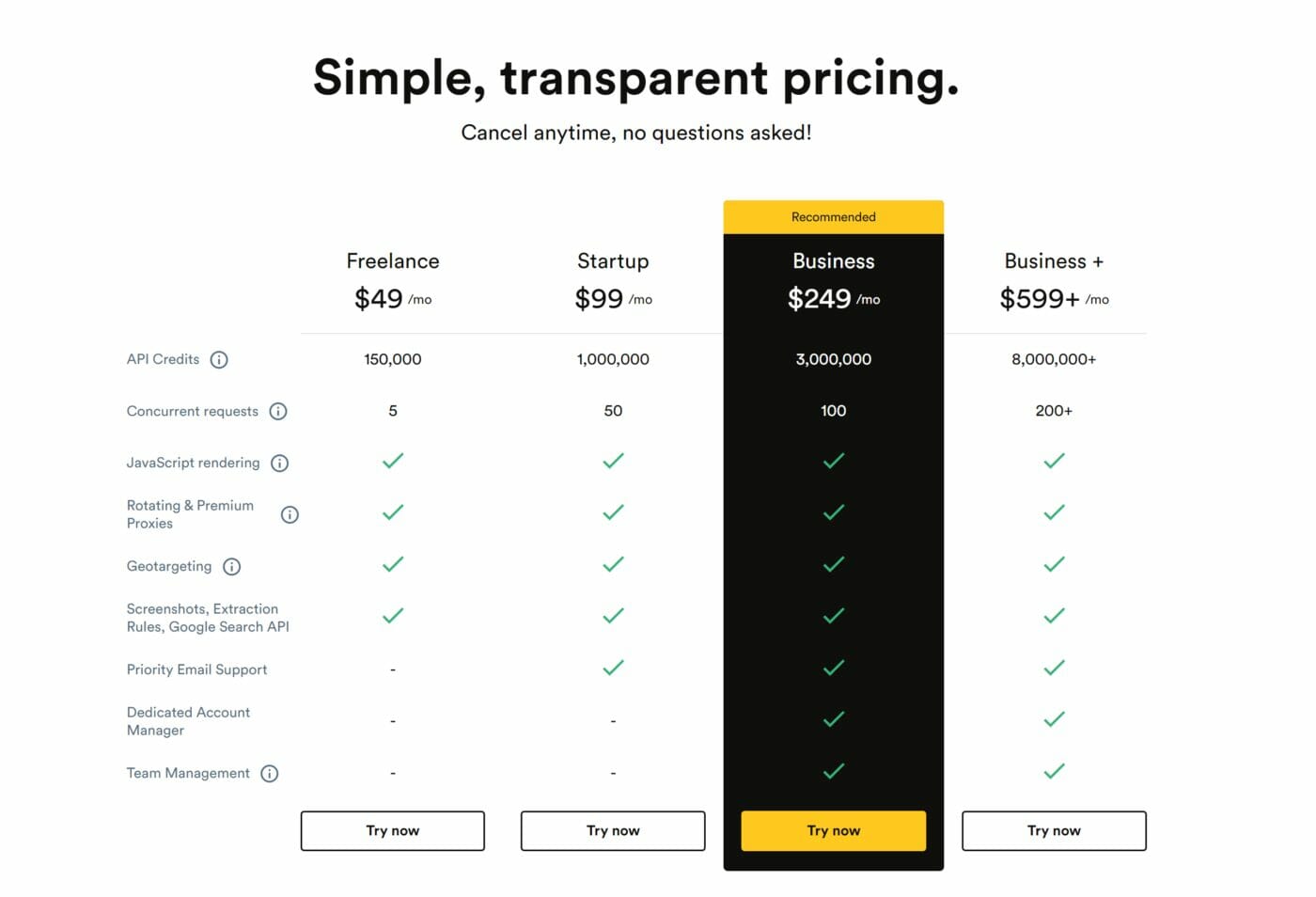
Im Trial von Scrapingbee bekommst du 1.000 API Request Credits kostenlos (Javascript Calls kosten 5 Credits). Das günstigste Paid-Package kostet 50€ im Monat und beinhaltet 150.000 Request Credits:
Meine Scraping Anwendungsfälle
Zugegeben, mein Geschäftsmodell besteht nicht aus Website-Scraping! Ich benötige hin und wieder mal Scraping-Skripte für einen SEO-Audit oder eine Datenbasis, die ich dann in PowerBi ausschlachten kann. Aber: ich nutze es in kommerziellen Projekten – entsprechend habe ich auch kein Problem mit der 50€ monatlichen Subscription.
In der Vergangenheit habe ich auch mit Beautifulsoup Daten von Websites erhalten oder via Power Query selbst. Bei Single Page Applications sind diese Tools aber normalerweise bereits an ihren Grenzen. Entsprechend müsste ich zusätzlich Headless-Chrome-Instanzen oder Selenium auf meinem Rechner kofigurieren, was aus meiner Sicht für meine Zwecke zu viel Overhead verursacht. Es ist nicht so, dass ich einen Server für die tägliche Beschaffung der Daten aufsetzen würde. Ich brauche es nur hin und wieder. Entsprechend ist der bisher einfachste Weg für mich ScrapingBee.
Ein weiteres Plus der API-Architektur ist, dass ich meine Requests im Vorfeld auch über Postman testen kann, ehe ich inden Code-Editor wechsel!
Credits
Ich habe zu Zwecken der Demonstration die Website von https://www.remind.me/ verwendet, weil ich sie gerade greifbar hatte und die Site eine sehr klassische SPA verwendet. Sorry, wenn ich mit meinen 5 Calls zusätzlichen Traffic verursacht habe!
