This is how Scraping / Crawling of Single Page Applications (SPAs) works – quick and easy.
Challenges of Single Page Applications
Single page applications (SPAs) are a particular challenge in the field of web scraping. They are mostly written in fancy Javascript frontend frameworks like Reacht, AngularJS or vueJS and load their contents after page load events via Javascript. This is a big problem for typical Python libraries like request, since these websites don’t return plain HTML on the initial HTTP request. In fact, most of the time SPAs only return a sparse HTML document with the text “Please enable Javascript!” before starting the JS-rendering-process.
Additionally: If the developers of the single page application are smart, they may even have configured the server to timeout after your initial request based on your IP. Crawling single page applications is hell!
ScrapingBee – easily scrape / crawl Single Page Applications with Python
I’m only going to introduce one way to do SPAs in Python in this post – the easiest and fastest I’ve found. More info on my specific use cases are explained in the next section. I discovered a small tool called Scrapingbee. The company behind Scrapingbee is based in France (Paris) and provides a simple API for its services. Its technology is flexible enough to crawl single page applications and integrates easily with Python.
With this small code snippet I get all the info I need for my case from a website or multiple subpages.
(Python Code)
# pip install scrapingbee
from scrapingbee import ScrapingBeeClient
import urllib.parse # just to make the response pretty
## Define list of URLs you want to crawl / scrape
urllist = ["https://www.remind.me/", "https://www.remind.me/strom/ratgeber/strommessgeraete-helfen-beim-energiesparen"]
## initiate ScrapingBee Client
client = ScrapingBeeClient(api_key="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
## loop through all urls in my list to extract information
for url in urllist:
response = client.get(url,
params = {
# render the SPA javascript
'render_js': 'True',
# do not block any important ressources
'block_resources': 'False',
# wait 2 seconds for the SPA to load
'js_scenario': {"instructions": [{"wait": 2000}]},
# return a json response
'json_response': 'True',
# only return the titel and meta description
'extract_rules': {"title": "title", "description": "//meta[@name=\"description\"]/@content"},
}
)
# prettify response
prettyResponse = response.json()
# print the repsonse content to the terminal or do whatever you want with it
print(prettyResponse['body'])The tool creates an API request via its client, which contains further specs on how to crawl the target URL. So I have the following request based on the SPA that I want to crawl. I can specify this through the “param” object:
- I want the javascript to be executed on the target page (render_js) and no resources to be blocked (block_resources).
- Then please wait a second in case the scripts need something (js_scenario + wait)
- I would like to have a json response (json_response)
- And via extract_rules I define via CSS selector or X-path what information I need from the page (I traditionally don’t need all content).
With the response I can do what I want. Just write it into the terminal or write the whole thing into a CSV at the end so I can analyze it further. I could even search the response for links and put it again into a scrapingbee call.
As a response, I only get what I really need from the page.
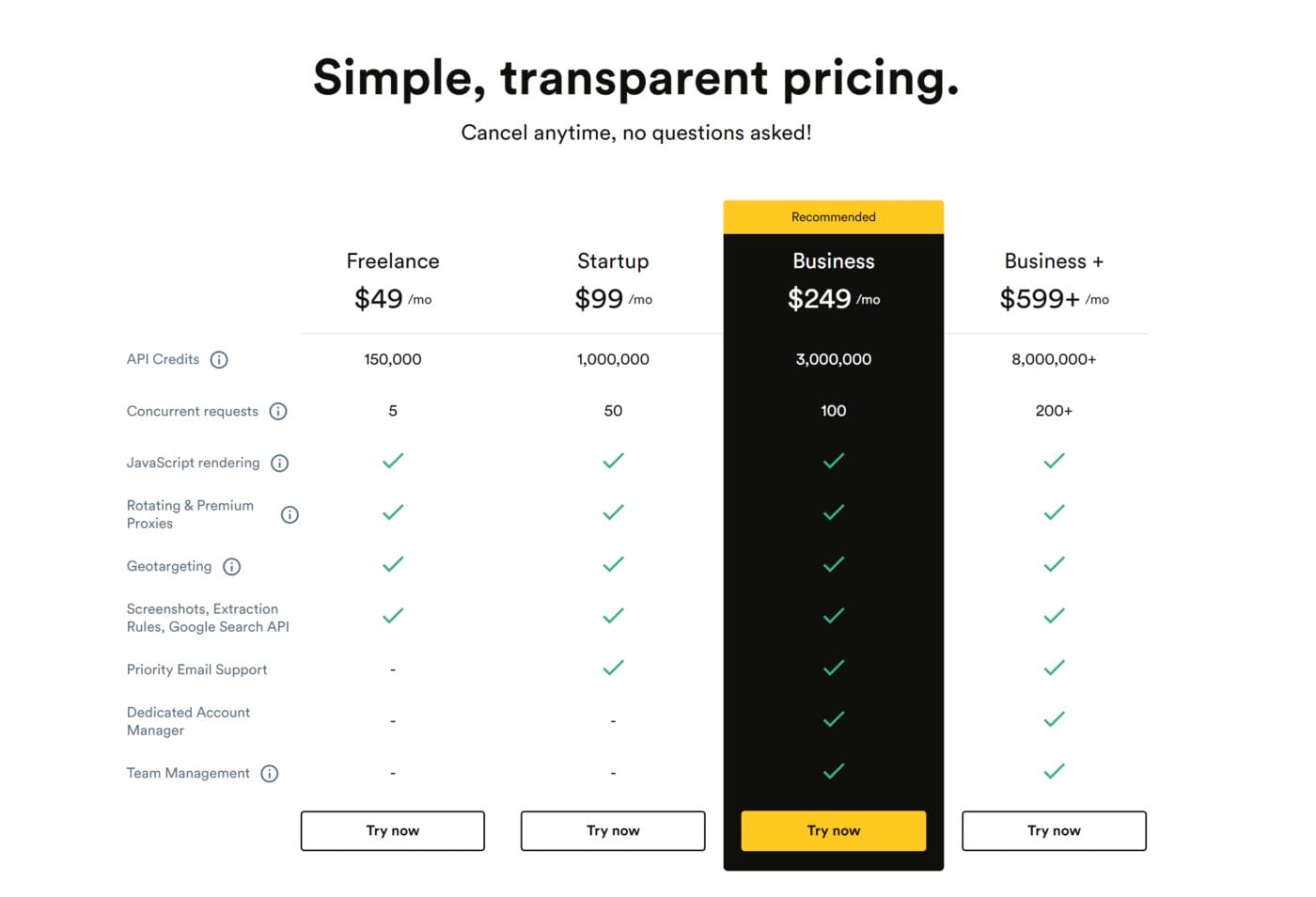
In the trial of Scrapingbee you get 1.000 API request credits for free (Javascript calls cost 5 credits). The cheapest paid package costs 50€ per month and includes 150.000 request credits:
My Scraping Use Cases
Admittedly, my business model is not website scraping! I do occasionally need scraping scripts for an SEO audit or a database that I can then cannibalize in PowerBi. But: I use it in commercial projects – accordingly I have no problem with the 50€ monthly subscription.
In the past I have also used Beautifulsoup to get data from websites or via Power Query itself. But for single page applications these tools are usually already at their limits. Accordingly, I would have to additionally co-figure Headless Chrome instances or Selenium on my machine, which in my view causes too much overhead for my purposes. It’s not like I would set up a server for daily data acquisition. I just need it every now and then. Accordingly, the easiest way for me so far is ScrapingBee.
Another plus of the API architecture is that I can also test my requests in advance via Postman before switching to the code editor!
Credits
I used the remind.me website for demonstration purposes because I just had it handy and the site uses a very classic SPA. Sorry if I caused extra traffic with my 5 calls!I used the website of https://www.remind.me/ for demonstration purposes because I had it just at hand and the site uses a very classic SPA. Sorry if I caused extra traffic with my 5 calls!
