In der Lektion 6 dieses SEO-Kurses lernst du, was Speedreading und HTML mit Suchmaschinen-Optimierung zutun haben. Außerdem beginnen wir mit dem Lesen des Dokuments.
Dies ist die Lektion 6 von 8 des Kurses SEO am Beispiel MS Word und Windows Explorer. Da diese Lektion didaktisch versucht einen Spannungsbogen aufzubauen und dem User eine eigene Lösungsvariante einräumt, findest du hier und an Stellen weiter unten eine Link-Option direkt in die Lösung zu springen.
Abstrakt: Du hast 2 Minuten 926 Wörter zu lesen!
Vor Beginn der Lektion 6 erinnere ich noch einmal an die Parameter aus Lektion 2: Du bist heute mal faul und dumm! In dieser Lektion ist Lesen ausdrücklich erlaubt. Allerdings wollen wir nicht allzu viel Zeit auf das Lesen unseres cosmos-markt.docx-Dokuments verwenden. Es warten schließlich noch Millionen andere Word-Dokumente in weit entfernten Netzlaufwerken auf dich.
In dieser Lektion ist es deine Aufgabe die inhaltlichen Thesen zu unserem Dokument ein für alle Mal zu validieren und eine umfassende Zusammenfassung des gesamten Textes zu geben. Weil wir mit der Zeit etwas knapp dran sind, gebe ich dir 2 Minuten Zeit, um den gesamten Text durchzuarbeiten. In Lektion 4 konnten wir ja bereits ermitteln, dass der Text 926 Wörter enthält. Der durchschnittliche Leser schafft zwischen 200 und 240 Wörter pro Minute!

+++ ZEIT ZUM NACHDENKEN +++
Du kannst dir nun ein paar Minuten Zeit nehmen, um dir selber eine Antwort auf die Fragen zu notieren:
- Wie schaffst du es in den gegebenen zeitlichen Parametern unsere inhaltliche These zu validieren und eine Zusammenfassung des Textes (mündlich) zu erzeugen?
- Beschreibe dein Herangehen in paar Steps / Stichpunkten!
- Versuche den Text tatsächlich mal nach diesem Vorgehen zu lesen bzw. zu analysieren!
Pro-Tipp: Die zeitliche Limitierung ist so gewählt, dass es theoretisch nicht möglich ist, den Text Wort für Wort von Beginn bis Ende zu lesen!
Alternativ kannst du auch weiter zur Lösung.
Lösung: Alles nur kein Fließtext lesen!
Gute Autoren haben die Angewohnheit wichtige Informationen zu markieren und vom Rest des Textes abzuheben. Insbesondere bei Text-lastigen Dokumenten ist dies erforderlich. Aber auch das Thema Struktur eines Dokumentes, wie wir es aus dem akademischen Umfeld kennen, kommt dir in dieser Lektion zugute. Es gibt Elemente innerhalb eines Textes, die nicht typische Paragraphen sind und nicht als solche formatiert sind. Solltest du also während des Lesens eines Textes priorisieren müssen, was du zuerst liest, ist es zu empfehlen auf folgende Elemente zu achten:
- Dokumenten-Titel
- Überschriften
- Fettungen (von Textpassagen)
- Bulletpoint-Aufzählungen
- Numerische Aufzählungen
- Tabellen
Die These ist: Es ist möglich einen gut geschriebenen Text grob zu verstehen, indem man lediglich diese 6 Arten von Elementen sucht und liest!

Der Dokumenten-Titel und die verschiedenen Zwischen-Überschriften sind zweifelsohne die wichtigsten Elemente, um eine Seite schnell und effizient zu lesen. Gute Autoren schaffen es eine gute Zusammenfassung der untergeordneten Absätze in jeder Zwischenüberschrift bereitzustellen und der Titel sollte ohnehin aussagekräftig verfasst sein. Innerhalb dieser Elemente gibt es auch Abstufungen in der Wichtigkeit: So gibt es z.B. eine Überschrift 1, die wichtiger ist als die Überschrift 2 und die Überschrift 3. In wissenschaftlichen Arbeiten unterliegen diese Dokumenten-Strukturen sogar teilweise noch zusätzlicher Regulierung. So kann es nämlich sein, dass Prüfer noch darauf achten, dass es im Dokument keine Überschrift 4 ohne eine klammernde Überschrift 3 gibt, dass mindestens zwei Überschrift-4-Elemente in einem Überschrift-3-Absatz gibt oder dass kein Text ohne Überschrift sich zwischen einer Überschrift 2 und einer Überschrift 3 befindet.
Fettungen von Wörtern und Textpassagen ist eine gängige Praxis, die wir schon früh lernen. Sei es in Word-Dokumenten oder E-Mails. Wir lernen: Wenn etwas wichtig ist, markiere es fett! Und genau dieser Umstand kommt dem Leser wiederum zugute, wenn er/sie über einen Text drüberfliegt und die wichtigsten Informationen extrahieren soll. Anfänger im Feld der Fettungen-Markup markieren lediglich wichtige Wörter innerhalb eines Fließtextes, echte Profis markieren ganze Textpassagen, sodass der Leser in der Lage wäre den gesamten Text nur anhand der Fettungen zu lesen (sogar unabhängig der Überschriften).
Aufzählungen – mit Bullet-Points oder Nummern – sind sehr nutzerfreundliche Elemente in langen Texten. Sie bereiten die Essenz einer Aussage auf und nehmen in manchen Fällen sogar ein Ranking der wichtigsten Informationen vor. Dieses Aggregationslevel macht sie ebenfalls zu guten Kandidaten für das priorisierte Lesen eines langen Textes. Entsprechend ist es zu empfehlen bei diesen anzuhalten, wenn man sie beim Scrollen findet.
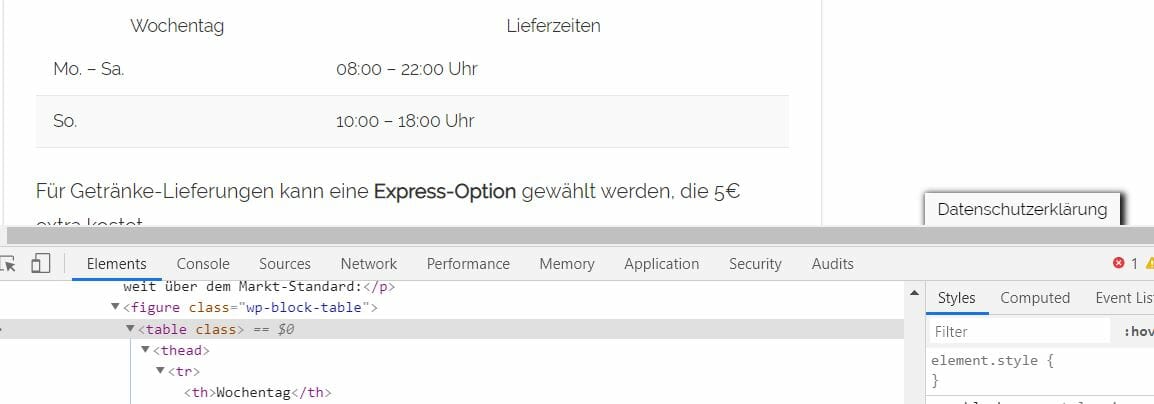
Tabellen in Dokumenten sind etwas seltener zu finden als Aufzählungen. Das mag daran liegen, dass sie das Layout eines Dokuments berühren und in manchen fällen ganze Texte optisch zerschießen können. Dennoch sind Tabellen maximal wichtig für das schnelle Verständnis von Sachverhalten. Ähnlichen wie Aufzählungen aggregieren sie Informationen und komprimieren sie auf kleine Flächen. Das wird einem klar, wenn man sich vorstellt, wie viel Raum / Buchstaben / Absätze eine ausformulierte Tabelle einnehmen würde:
| Visits | Okt 19 | Nov 19 | Wachstum % |
|---|---|---|---|
| /supermarkte/bofrost/ | 100 | 120 | +20% |
| /supermarkte/bringmeister/ | 310 | 290 | -6,5% |
Die Unterseite /supermarkte/bofrost/ hatte im Oktober 2019 100 Visits. Im November 2019 hatte sie 120 Visits. Im Vergleich zwischen den Monaten entspricht das einem Wachstum von 20 Prozent. Die Unterseite /supermarkte/bringmeister/ hatte im Oktober 2019 310 Visits. Im November 2019 hatte sie 290 Visits. Im Vergleich zwischen den Monaten entspricht das einem Rückgang der Visits um 6,5 Prozent.
Ein wichtiges Element, das wir schnell scannen würden beim Lesen des Dokuments sind Bilder! Allerdings unterliegen Bilder einer anderen Analyse-Mechanik als die oben genannten Text-Elemente im Suchmaschinen-Kontext. Entsprechend werden Bilder in der Lektion 7 noch einmal separat behandelt.
Transfer: So übersetzen Überschriften, Listen & Co. in HTML
Wenn wir uns zu Zwecken der Transferleistung jetzt kurz in die Rolle einer Maschine versetzen würden, die versucht das Leseverhalten eines Menschen zu simulieren, müssten wir auf unserer Website nach folgenden Stilmitteln der Textgestaltung suchen:
Übersicht wichtiger Speed-Reading Elemente innerhalb eines Dokuments:
- Dokumenten-Titel
- Überschriften
- Fettungen (von Textpassagen)
- Bulletpoint-Aufzählungen
- Numerische Aufzählungen
- Tabellen
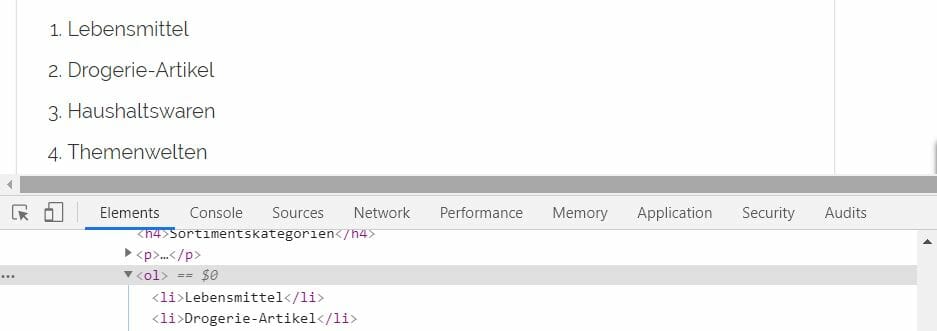
Wie es der Zufall so will, gibt es für all diese Elemente spezifische Kennzeichnungen (HTML Markup), die diese Elemente innerhalb des Quelltextes vom Rest unseres Textes abheben! Der typische Fließtext, wie wir ihn kennen, ist auf Websites meistens in einem <p></p> Element eingeschlossen. Eine numerische Aufzählung wir finden wir hingegen innerhalb eines <ol></ol>-Elements (ol = ordered list). Wenn wir z.B. die Liste mit den wichtigen Elementen aus dem letzten Absatz in HTML umsetzen wollten, würden wir sie wie folgt schreiben:
<p>Übersicht wichtiger Speed-Reading Elemente innerhalb eines Dokuments:</p>
<ol>
<li>Dokumenten-Titel</li>
<li>Überschriften</li>
<li>Fettungen (von Textpassagen)</li>
<li>Bulletpoint-Aufzählungen</li>
<li>Numerische Aufzählungen</li>
<li>Tabellen</li>
</ol>Wir erkennen hier sowohl ein „normales“ Textelement mit den <p>-Tags und die Tabelle als <ol>-Tag mit einzelnen Aufzählungselementen <li> (List Elements).
Und für alle oben genannten Dokumente gibt es auch entsprechende HTML-Counterparts.

Gegenübergestellt würde dies wie folgt aussehen:
| Word-Dokument | HTML-Markup |
|---|---|
| Dokumenten-Titel | <h1> |
| Überschriften | <h2>, <h3>, <h4>, … |
| Fettungen (von Textpassagen) | <strong> |
| Bulletpoint-Aufzählungen | <ul> |
| Numerische Aufzählungen | <ol> |
| Tabellen | <table> |
So einfach es klingen würde, müsste der Google Bot nun lediglich die HTML-Seite herunterladen und die jeweils gekennzeichneten Inhalte extrahieren, um eine priorisierte Datengrundlage zu Analysezwecken zu erhalten. Die analysierten Text-Passagen würden im Umkehrschluss wieder in die inhaltliche Analyse des Dokuments einfließen.
Hier die Beispiele wie die einzelnen Prio-Elemente innerhalb einer Website im Quelltext zu finden sind:
Dokumententitel HTML Markup (H1)
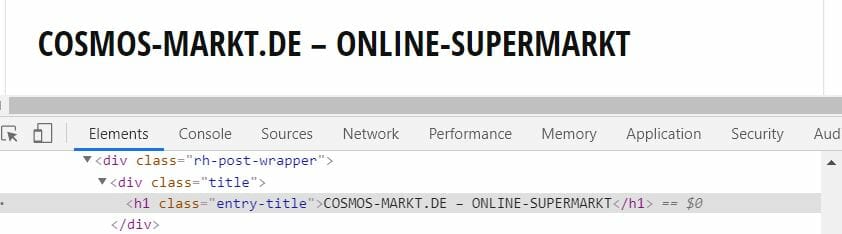
Zwischenüberschriften HTML-Markup (H3 + H4)
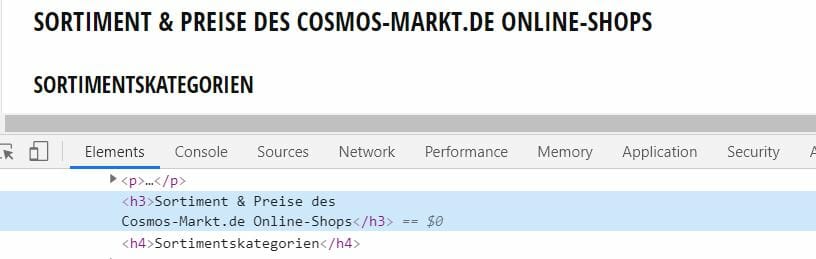
Fettungen HTML-Markup (strong)
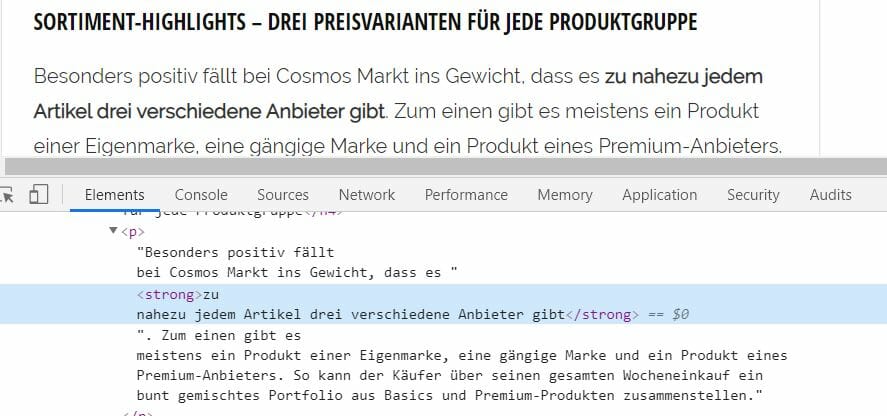
Aufzählungen HTML Markup (ul + ol)
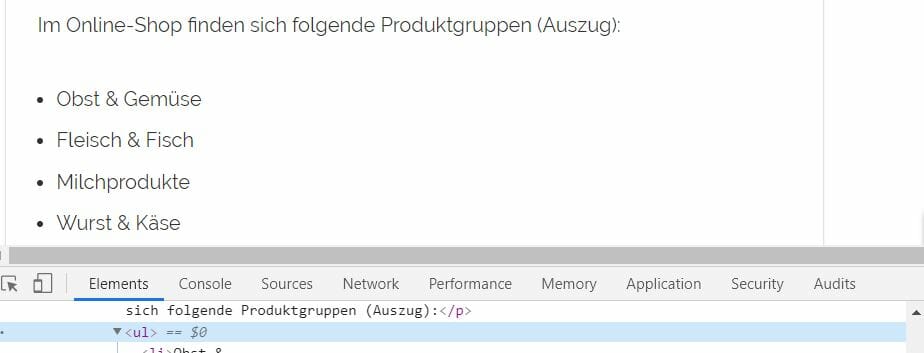
Tabellen HTML Markup (table)
Konkret: Bedeutung von Text-Markup in der Suchmaschinen-Optimierung
Bei der Verwendung von unterschiedlichem HTML-Markup innerhalb von text-lastigen Websites kommen Suchmaschinen-Optimierung und User-Experience sehr nah zusammen: Denn niemand liest gerne Bleiwüsten aus 900 Wörten mit ein nur ein paar Absätzen dazwischen.
Die Wichtigkeit von Überschriften innerhalb von Dokumenten ist für gute Rankings in der Welt der Suchmaschinen-Optimierung unumstritten. Daher sollte jeder deiner Websites mindestens eine H1-Überschrift und eine H2-Überschrift enthalten. Die Ausgestaltung der gesamten Überschriften-Hierarchie ist in den vergangenen Jahren aber ein wenig zu einem Streitpunkt unter SEOs geworden. Ein Lager argumentiert für eine strikte Überschriften-Struktur, in der es nur ein H1 und eine H1 pro Seite geben darf, andere wiederum sagen, dass die Anzahl der Verteilung egal ist, solange die Hierarchie eine Systematik hat. Wichtig ist es, sich zu merken, dass die hierarchische Verwendung von H1, H2 und mehreren H3-Elementen definitiv zu einer besseren Nutzererfahrung führt, wie man es z.B. auch an Listical-Formaten nachvollziehen kann.
Die Verwendung von Aufzählungen und Tabellen haben in den vergangenen Jahren gemischte Eindrücke unter Experten hinterlassen. Es gibt Seiten ohne diese Elemente, die gut ranken und wiederum Seiten mit diesen Elementen, die keine signifikanten Rankings erzielen. Allerdings würde ich mit wünschen, dass du als Website-Verantwortlicher auch in Zukunft auf Tabellen und Aufzählungen setzt – und wenn es nur für eine bessere Lese-Erfahrung deiner Nutzer ist.
Häufig gestellte Fragen zu dieser Lektion
Die Frage ist nicht pauschal zu beantworten, sondern lediglich in Abhängigkeit von der kognitiven Fähigkeit eines Menschen. Es wird davon ausgegangen, dass normale Leser zwischen 200 und 240 Wörter pro Minute lesen können, wohingegen langsame Leser teilweise nur 100 Wörter pro Minute schaffen. Schnelle Leser sollen ca. 400 Wörter pro Minute lesen können, während sehr ausgesuchte Individuen bis zu 1000 Wörter pro Minute lesen können sollen. Wie hoch das entsprechende Verständnis hinter dem Gelesenen ist, ist dabei noch eine weitere Dimension.
Bildverarbeitung ist für Software und Maschinen außerordentlich schwierig im Vergleich zu Menschen. Auch wenn Bilder teilweise ausgelesen werden, wird die Analyse von Bildern separat in der Lektion 7 behandelt?
Wenn du einen Text in Word „fetten“ möchtest, kannst du dies entweder über die Werkzeugleiste im Programm machen oder über die Tastenkombination Strg+Shift+F nachdem du den entsprechenden Text markiert hast.